




大模型的背景分析与展望近年来,人工智能技术发展迅速,尤其是机器学习和深度学习技术的进步催生了大模型时代的到来。大模型可以在短期内遍布各技术领域,其突然爆发的原因是由大数据和大算力的发展驱动。大模型需要海量的数据进行训练,数据资源的增长速度在近年来几乎每年翻倍。相比5到10年前,全球范围内能够开发大模型的机构已不在少数。如今,不仅科技公司、学术机构和研究团队,甚至学生团队都能发布自己的大模型。大数据资源的丰富为大模型的发展奠定了基础。

大模型还需要强大的算力支持,特别是人工智能应用领域的智能算力。我国智能算力规模在2021年达到202EFLOPS,位居全球第二,增速高达85%。通用算力、超算算力和边缘算力也均有较快发展。强大的算力资源为大模型提供了有力支撑。大模型代表了人工智能技术的最高水平,它拥有海量的参数和计算资源,需要大数据和强大算力的支持。大模型的出现标志着人工智能已进入智能时代,其带来的影响将深刻改变我们的生活和工作方式。未来,大模型将进一步发展。

模型规模将继续扩大,参数数量将达到千亿级以上;模型的泛化能力和健壮性将进一步提高;多模态模型将更加普及,实现多感知融合;模型的可解释性和健壮性也将成为研究热点。大模型时代正处于起步阶段,它所带来的机遇和挑战同时存在。如何更好地运用大模型,让其真正造福人类,是我们需要思考的问题。 自然语言处理领域的深度学习模型飞速发展,代表性模型如谷歌的BERT、OpenAI的GPT以及百度的文心,参数规模扩张到亿级,使用的数据量也显著增加,大大提高了模型的理解和生成能力。

这些模型通常采用预训练和微调的方法,首先在海量未标注数据上进行自监督学习,然后根据具体任务进行少量数据微调,实现更优的识别、理解、决策和生成效果。深度学习模型在产业智能化升级中表现出巨大潜力,可应用于搜索、推荐、智能交互、生产流程变革等场景。但模型也面临挑战,如高昂的计算成本、数据质量和安全问题、模型可解释性和可信度问题。模型的参数量庞大,可以更好捕获数据中的复杂关系和模式,实现各种任务的出色性能。
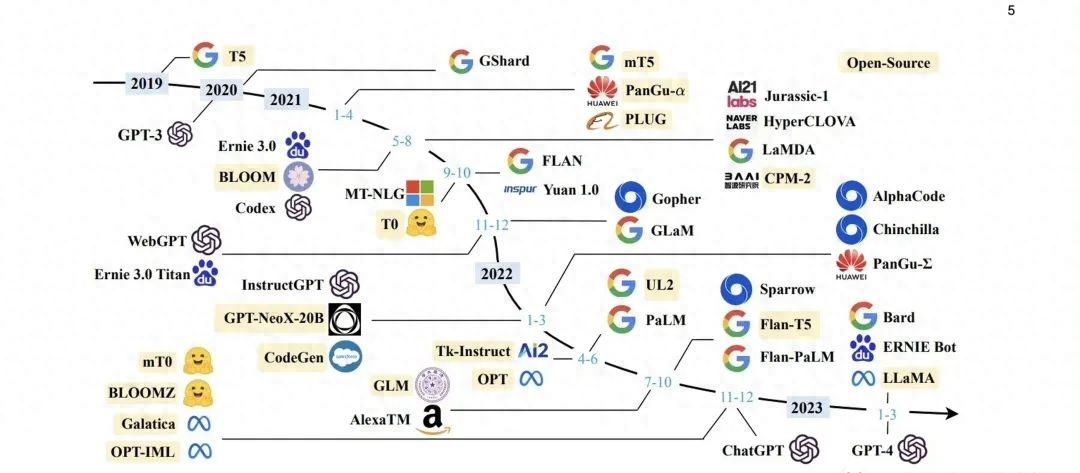
模型通常有更深的神经网络结构,包括多个层和子网络,可以进行多层次特征提取和抽象。 模型通常在大规模数据上预训练,获取广泛知识,然后在特定任务上微调,实现更好性能。预训练-微调策略在自然语言处理领域非常成功。由于模型的规模和复杂性,需要大量计算资源进行训练和推理,通常需要GPU或TPU等高性能计算单元。算力、数据和算法模型相互依存,共同构建模型应用生态。算力影响训练速度和模型规模,更强大的算力支持更大的模型、更长的训练时间和更高的训练精度。
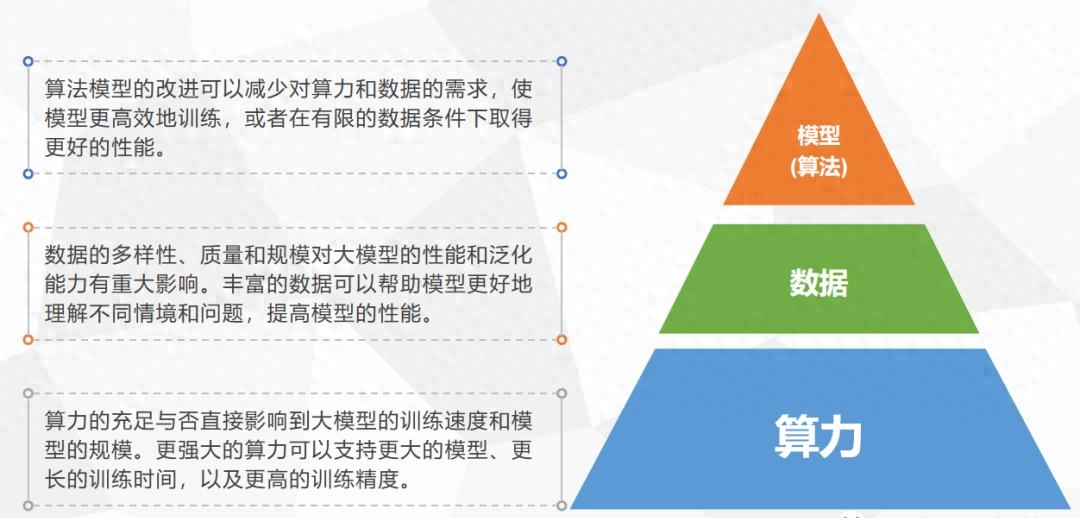
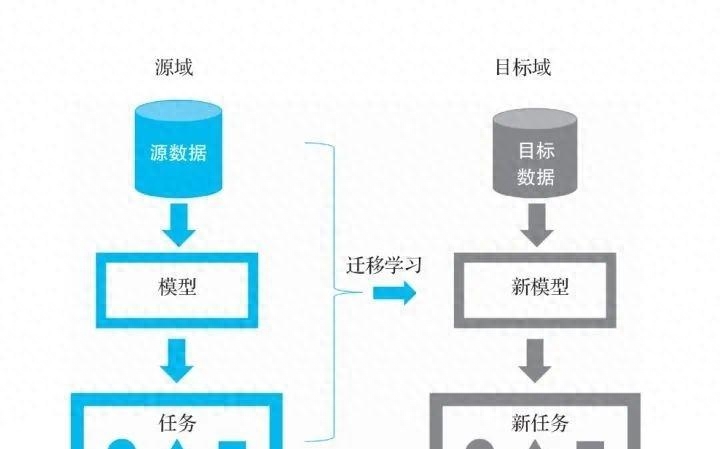
数据的多样性、质量和规模对模型性能和泛化能力有重大影响,丰富的数据可以帮助模型更好地理解不同情境和问题,提高性能。算法模型的改进可以减少对算力和数据的需求,使模型更高效训练,或者在有限数据下取得更好性能。 深度学习模型的主要能力是迁移学习、表达能力和创造学习。模型具有强大的知识和记忆能力,可以从海量语料中学习丰富语义和知识表示,在下游任务中迁移学习。模型拥有人类一样的理解能力,可以生成新信息并理解复杂语言现象。
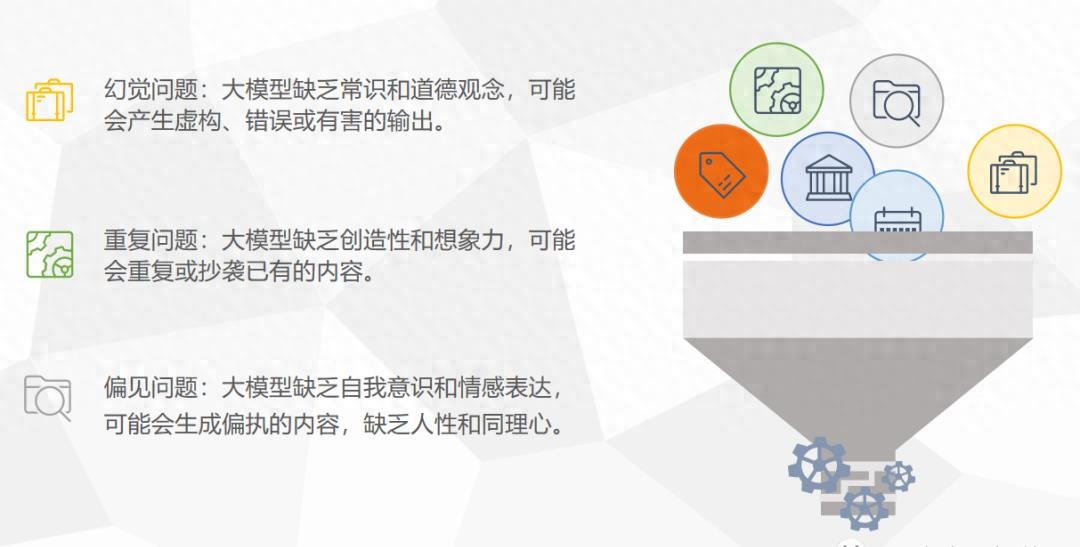
模型还具有推理、规划和学习能力,可以根据目标进行推理和决策,通过反馈与环境交互,甚至塑造环境。它可以根据现有数据推测未来,根据描述创作符合条件的作品。 深度学习模型也面临问题,如常被诟病的幻觉问题。模型缺乏常识和道德观念,可能产生虚构、错误或有害输出。模型还存在重复输出和偏见问题,缺乏创造性和想象力,会重复输出相似内容或偏执内容,被视为缺乏人性和同理心。随着技术发展,这些问题会逐渐改进。未来AI agent会更加智能,更像真人。
深度学习模型正在企业之间的竞争中发挥重要作用,明年这种竞争会更加激烈,尤其是大企业之间。深度学习模型应用将逐渐渗透各行各业,如金融、医疗、零售和制造业。互联网企业用户敏感度高,深度学习模型对其冲击更大。总之,深度学习模型技术发展迅速,应用广泛,值得持续关注。 深度学习模型正飞速发展,不断创新和进步,未来AI的发展会以什么样的速度和方向发展呢 根据你的要求,我对原文进行了重新撰写,具体内容如下:大模型时代的未来发展方向引人瞩目。

2023年4月,中央政治局会议明确提出要重视人工智能大模型的发展。目前,大模型应用已广泛用于民生和军事领域。但是,大模型发展面临的机遇和挑战并存。机遇在于,大模型能够解决多类问题,并带来巨大经济效益。挑战在于,大模型涉及的参数太多,难以在各个领域达到专业水平。 大型互联网企业如今已无法回避大模型。大模型生态的缺失意味着企业发展或受制于人。小企业难以与大型公司竞争,更多依附于大型公司的生态系统发展业务。

大模型发展已成为各大互联网公司的必选项目,要么积极拥抱,要么等待出局。与企业竞争相比,政府对大模型发展更加倾注资金和政策支持。截至2023年8月,北京、上海、杭州、苏州等城市相继出台政策,为大模型研发提供最高5000万元补助。其中,上海发布“模都倡议”,打造人工智能开源生态产业集群,扶持大模型企业集聚。杭州每年评选10个大模型应用项目,最高提供500万元补助。苏州提出2025年智算目标,为大模型企业提供最高1000万元资金支持。

武汉“光谷软件十条”鼓励大模型开源项目,最高提供3000万元补贴。北京制定中关村科学城算力补贴计划,为大模型研发提供最高1000万元补助。通用模型目前占据大模型应用的主导地位。通用模型能解决多类问题,如ChatGPT和文心一言等,可实现人工智能对话、文章写作、数学计算和代码编程等。通用模型的弱点是参数太多,在专业领域表现不如人工。这是因为训练数据涵盖各领域场景难以准备充分,且要求各专家判断模型输出的准确性,这本身就是一大难题。

总而言之,大模型发展方向值得期待。但大模型面临的机遇和挑战并存。如何在各个专业领域达到人工智能,还需要更多数据和专家支持。大模型应用要在民生和军事领域获得更大进展,这需要政府和企业共同努力。希望大模型能够在保障国家安全的同时,也造福人类社会。 大模型的未来前景广阔,尽管面临参数膨胀和设备部署的挑战,但技术进步必将促使大模型越来越平民化。 近年来,大模型能力不断提高,但模型参数也在急剧增加。参数过多会导致过拟合和训练时间过长,给硬件带来较高要求。

理论上增大参数能提高模型能力,但实践中并非唯一选择。相反,降低参数让模型能在不同设备上部署,提高效率和节省算力,这是大模型发展的趋势。如微软Phi模型和上海人工智能实验室InternLM模型在保证能力的前提下瘦身参数,适应实际应用。随技术进步,大模型不再“大”,会像第一台计算机一样,从房间大小变为掌上工具。目前,专业大模型的效果优于通用大模型。同参数下,专用模型在指定任务上的效果超过通用模型,未来实际应用价值也更高。

如MathGPT解决数学问题和CodeGPT解决编程问题,这些专用大模型在各自领域,能力远超通用大模型,商业价值也更高。大模型发展将从通用模型发展到专用模型,再到世界模型。构造自主AI需要预测世界模型,这需要多模态预测能力。大模型发展既关乎企业发展,也关乎国家竞争力,更与人类走向AGI有关。尽管面临参数膨胀和设备部署的挑战,但大模型的未来前景广阔。理论上增大参数能提高模型能力,但实践中并非唯一选择。

相反,降低参数让模型能在不同设备上部署,提高效率和节省算力,这是大模型发展的趋势。随技术进步,大模型会越来越平民化。目前,专业大模型的效果优于通用大模型。未来,大模型发展将从通用模型发展到专用模型,再到世界模型。构造自主AI需要预测世界模型,这需要多模态预测能力。大模型发展既关乎企业发展,也关乎国家竞争力,更与人类走向AGI有关。大模型发展面临哪些机遇和挑战专业大模型与通用大模型有何区别构造自主AI需要什么样的大模型这些问题值得我们深思。
大模型发展之路任重而道远,需要我们共同探讨与努力。
您可能关注: AI 大模型 AI前景
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表炎黄立场。
